


Hydra Launches: Serverless Realtime Analytics on Postgres



"Unlock realtime analytics on live data in seconds."

Founded by Joseph Sciarrino & JD Dance
Hey everyone! Meet Joe and JD pictured in Hood River, Oregon. Building Hydra has been a wild ride, but they found a way to have fun.

Hydra is Serverless Realtime Analytics on Postgres
By separating compute from storage, Hydra enables compute-isolated analytics and bottomless storage. It is designed for low latency applications built on time series and event data.
Try Now! (free)
Enable in seconds
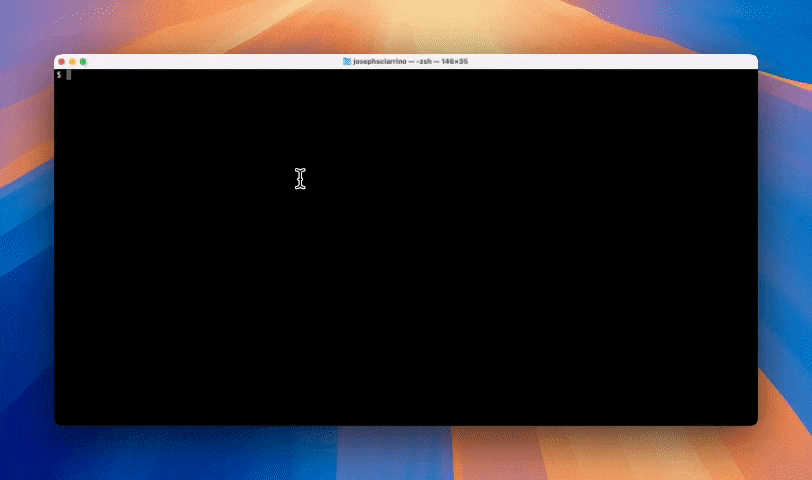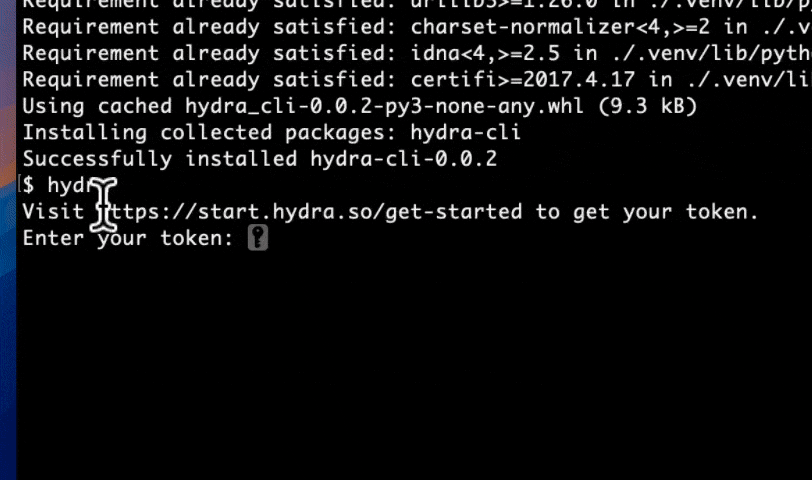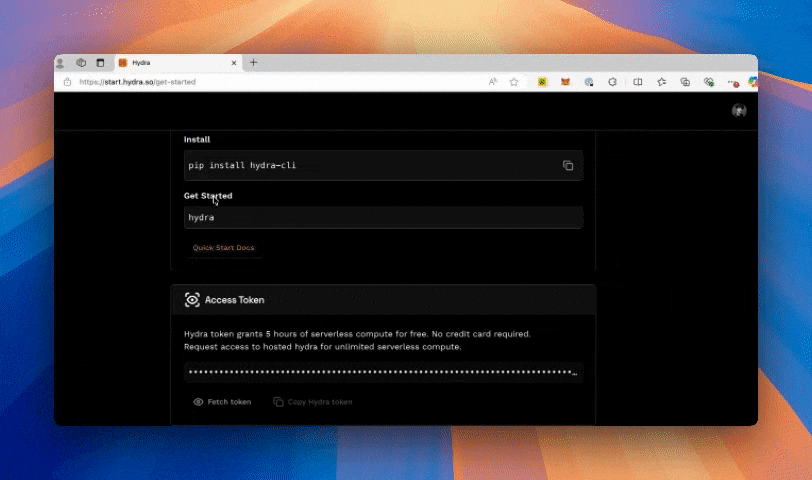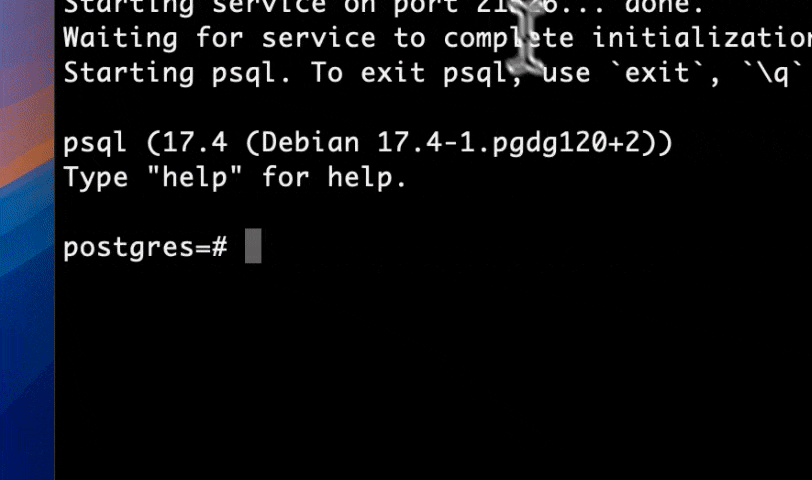
Set up is simple. To unlock serverless realtime analytics on Postgres, run:
pip install hydra-cli
For setup:
hydra
- Fetch your hydra token, paste in to enable Hydra.
- Create analytics schema / tables and insert data (Quick Start docs).
- Voila - run queries, get insights in milliseconds.
Problem
For decades, there’ve been two core problems with analytics on Postgres:
Slow - Aggregates and complex queries can take minutes to return results from large data sets.
Resource Contention - Expensive analytics queries hog Postgres’ RAM / CPU resources and impair transactional performance. In other words, the entire app slows down, which makes users unhappy.
Solution
Fast
Hydra returns analytics queries 400X faster than standard Postgres. Hydra uses duckdb to perform isolated serverless processing on these tables in Postgres. In fact, Hydra is faster than most specialized analytics databases.
If you’re running AWS RDS, AWS Aurora, Heroku Postgres, Supabase, Fly Postgres, Render Postgres, GCP Cloud SQL, etc.. you can improve expensive analytics queries by 400X by using Hydra.

Fun fact: the Snowflake instance (128x4XL) in the benchmark is $100k / month.

These are results from ClickBench which represents a typical workload in the following areas: clickstream and traffic analysis, web analytics, machine-generated data, structured logs, and events data. The table consists of exactly 99 997 497 records — rather small by modern standards but allows tests to be performed in a reasonable time.
Isolated, serverless processing
Using Hydra there is no impact on Postgres’ RAM / CPU resources when reading from or writing to an analytics tables.
As a result, here are more cool things Hydra can do: zero-copy clones for scaling read replicas, automatic caching, write isolation, bottomless storage with high data compression, and more.
How it works

Hydra integrates duckdb execution and features with Postgres using pg_duckdb, an open-source project the founders co-developed with the creators of DuckDB.
FAQ
Yes, you can join between an analytic table and a standard row-based table.
Yes, you can write (insert & update) to analytics tables.
Yes, Hydra is identical to using standard Postgres.
Yes, data inserted into an analytics table is automatically converted into analytics-optimized columnar format.
Tell Hydra you are creating an analytics table by including the ‘using duckdb’ keyword - that’s it.
Hydra is best for
Hydra is both a row and columnstore, so you can use it for standard Postgres work, like multitenant apps, as well as analytical work, like monthly reporting. Here are several cool Hydra use cases that blend both transactional & analytics — more in their use case docs.
- Time series, Logs, Events, Traces.
- Monitoring & Telemetry.
- Financial Services.
- Observability & Metrics.
- Cybersecurity & Fraud Detection.
- Web & Product Analytics.
- IoT.
- Realtime ML / AI.
Ok, but why use Postgres instead of … [insert favorite tech]?
It’s true, there are many specialized analytics databases. Reviewing the benchmark above, the majority of analytics databases are actually slower than Hydra. Regardless, isolated analytics databases produce their own set of challenges and costs.
Data pipelines (ETL)
Traditionally, an analytics database is isolated, and in most cases, engineers must set up data pipelines for data movement and transformation between Postgres, S3, and the analytics db. Pipelines aren’t cheap. Also, there’s pipeline latency bottlenecking how stale the analytics are. And when pipelines break — because they do — you’re stuck with downtime and wrong results.
Hydra side-steps the latency and costs of data pipelines entirely with full support for inserts and updates on columnar files in analytics tables.
Overweight design
Many use cases don’t justify a heavy setup. During the time the founders worked at Heroku, they saw many transactional apps that only need a couple high level aggregates and a few complex analytical queries to return quickly. Hardly OLAP (online analytical processing) and not really HTAP (hybrid transactional and analytical processing) - just apps in need of a speed boost.
The most heavyweight option, data warehouses like BigQuery, are good at “big queries”, but not great at smaller, rapid analytics queries that’re more common with applications, rather than monthly reporting.
These traditional approaches are too heavy, can be brittle, and introduce extra costs and latency your startup doesn’t need.
Does Hydra have a hosted cloud offering?
Yes, and it’s awesome.
Learn More
🌐 Visit www.hydra.so to learn more.
⚡ Try now!
🌟 Useful links - website, docs, local dev guide, analytics guide, architecture, changelog.
👣 Follow Hydra on LinkedIn & X.



Simplify Startup Finances Today
Take the stress out of bookkeeping, taxes, and tax credits with Fondo’s all-in-one accounting platform built for startups. Start saving time and money with our expert-backed solutions.
Get Started
.png)








